In today’s technology and content optimization environment, knowing how to extract keywords from a text has become an essential skill. This process also has applications in fields such as machine learning, data analysis, and marketing.
Below, we’ll explore various techniques, tools, and methods to achieve keyword extraction, with an emphasis on specific methods, such as using Python and popular libraries like NLTK. By the end, you’ll understand how to choose the right method and leverage these resources for free to optimize content and data analysis in multiple contexts.
Why Extract Keywords from a Text?
With the abundance of information available, it is impossible for a person to review and understand all of it; in this sense, extracting keywords from a text facilitates content analysis, strategy creation, and understanding of main themes in large volumes of data. In this context, keywords play an important role in representing the essence of a document (Jayasiriwardene y Ganegoda, 2020), and it’s essential to extract them quickly and accurately for composition analysis (Jiang et al., 2024).
The process of keyword extraction is used to identify terms and phrases that accurately represent a text’s content, and it’s key in several areas:
- SEO and Digital Marketing: Improves search engine optimization by finding the most relevant words in specific content. Additionally, online reviews have become a crucial reference for consumers when choosing and purchasing products or services (Wu et al., 2024); therefore, analyzing these reviews has become one of the main inputs for developing business strategies.
- Data Analysis and Machine Learning: A fundamental step in natural language processing (NLP), essential in machine learning models that aim to categorize or classify texts. Liu y Jiang (2023) tested technologies related to natural language processing (NLP) and text analysis to address the issue of symptom analysis and symptomatic treatment for healthcare workers and patients after large-scale infectious disease outbreaks.
- Content Automation and Summarization: Helps synthesize information and generate summaries automatically.
- Creating Educational Exercises: Pascual et al., (2023) highlight that automatically detecting keywords could be a starting point for creating capable applications in the education sector to automatically generate questions and exercises.
Specific applications include keyword extraction in job descriptions or websites, allowing companies and professionals to understand essential competencies in the job market or improve the relevance of their sites.
Basic Methods for Extracting Keywords
There are several basic approaches to extracting keywords from a text. The most common include:
- Word Frequency (Term Frequency) This method calculates the frequency of each word in the text. The more times a word appears, the higher the likelihood of it being relevant. However, this method doesn’t consider the importance of the word in the context of the overall corpus.
- TF-IDF (Term Frequency-Inverse Document Frequency) The TF-IDF algorithm is a simple and efficient method to extract keywords from a text (Zou et al., 2024). TF-IDF is widely used in SEO and data processing as it combines word frequency with the inverse of its frequency in a set of documents, allowing the identification of unique and relevant terms in a specific text compared to a broader corpus.
- RAKE (Rapid Automatic Keyword Extraction) RAKE is an extraction algorithm that identifies keywords by considering word frequency and co-occurrence. It is ideal for analyzing short texts such as product descriptions or article titles.
- Simple Statistical Models Methods such as bigram and trigram analysis help identify relevant phrases in longer texts. In this approach, word combinations, like “machine learning” or “keywords,” appear with a higher probability of relevance.
Keyword Extraction with Machine Learning
Using machine learning to extract keywords from a text allows you to leverage models that adapt and improve over time. There are several popular techniques, including:
- Regression Models Regression models can predict the relevance of a word within a text based on its position and frequency. They are effective for highly specific texts, such as job descriptions or review analysis.
- Supervised and Unsupervised Algorithms Some algorithms, like decision trees or clustering, organize content into categories to find high-relevance keywords. This is useful in contexts such as keyword extraction on websites or in job descriptions.
- Advanced NLP Models Tools like BERT (Bidirectional Encoder Representations from Transformers) and KeyBERT use embeddings to better understand each word’s context within a text, achieving highly accurate results.
How to Extract Keywords with Python and NLTK
For those seeking a programmatic solution, Python and its library NLTK (Natural Language Toolkit) are an excellent option. This programming language allows for quick and effective keyword extraction, especially for advanced users. Below is a description of how to implement keyword extraction with Python and NLTK:
Basic Steps
- Install NLTK:
pip install nltk- Import Necessary Libraries:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize- Prepare the Text and Tokenization:
text = "Insert the text from which you want to extract keywords."
words = word_tokenize(text)- Remove Stop Words and Generate the Keyword List:
stop_words = set(stopwords.words('english'))
keywords = [word for word in words if word.lower() not in stop_words]This method will allow you to obtain a quick and simple list of keywords. It’s ideal for small projects or if you need to extract keywords from a text in Python on an occasional basis. More advanced tools like spaCy or Gensim offer even greater accuracy for complex machine learning projects.
Online Tools for Keyword Extraction
There are several free online tools that offer the functionality of extracting keywords from a text without the need for programming. Some of the best are:
Table 01. Online tools for extracting keywords from a text.
| Tool | Advantages | Disadvantages |
|---|---|---|
| WordCount Keyword Extractor | – Easy to use and fast. – Ideal for short texts and basic SEO optimization. | – Does not analyze semantic context, only frequency. – Limited customization options and no support for text in other languages. |
| Cortical.io Keyword Extractor | – Uses advanced semantic analysis, highlighting relevant words in context. – Provides additional tools to visualize concepts. | – Limited to certain topics; complex for users without experience in semantics. – Free version limited in text volume and number of daily extractions. |
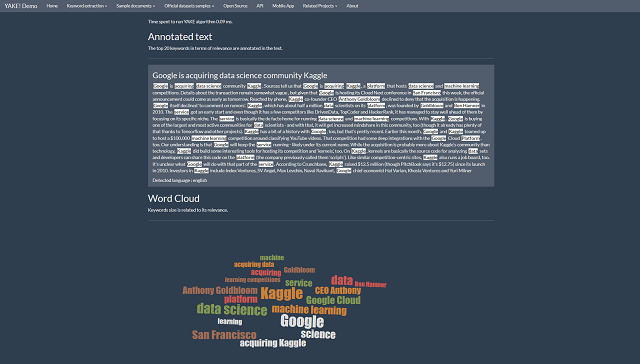
| Yake! | – Yake! does not require an external corpus to calculate keyword relevance, allowing relevant terms to be extracted directly from the analyzed text. – Supports multiple languages, making it accessible and versatile for content in different languages. – Methodology works effectively for both lengthy texts and short fragments. | – Focuses on the statistical relevance of words and phrases but does not consider deep semantics or context. – Lacks advanced visualizations, which may make comparative keyword analysis across texts difficult. – Accuracy may decrease in highly technical or specialized texts. |
| KeyBERT (Based on BERT) | – Analyzes semantic context in-depth and extracts words with high precision. – Ideal for lengthy texts and complex content analysis. | – Requires technical knowledge for integration; needs Python if used offline. – Online version is limited; free version restricted for large-scale analysis. |
| Semantria (by Lexalytics) | – Analyzes semantics and sentiment, useful for market research and text analysis. – Excellent for in-depth analysis beyond keywords. | – High costs and complex setup; not accessible to inexperienced users. – Limited to business context analysis. |
| RiteTag Keyword Tool | – Ideal for detecting keywords and hashtags on social media, especially on “X” (Twitter). – Free and easy to use for social media content creation. | – Focused only on social media; does not analyze texts outside this context. – Not useful for analyzing long texts or web content. |
By using these free online keyword extraction tools, you can quickly identify important terms in a text without resorting to programmed solutions. In this regard, it is important to mention that Hongwiengchan y Qu (2023) compared keyword extraction for crowdfunding projects (Kickstarter and Indiegogo) using the RAKE, NLTK, LIAAD/YAKE, BERT, and Gensim models, and concluded that the NLTK model is the most efficient.
Keyword Extraction in Specific Contexts
Keyword Extraction from a Website
Extracting keywords from a website helps to better understand the content and relevance of each page. This can be done manually or with specific SEO tools like Ahrefs or SEMrush. Free online tools also offer quick solutions for this type of analysis.
Keyword Extraction in Job Descriptions
In the professional realm, extracting keywords from a job description is useful for both candidates and recruiters. The keywords here are often related to skills, competencies, and specific requirements. Candidates can use these keywords to tailor their resumes to the expectations of recruiters.
Best Practices and Advanced Tips
To optimize keyword extraction, consider the following tips:
- Semantic Context: Instead of just counting the frequency of words, evaluate the context of each term using models like Word2Vec or BERT. This will improve the accuracy of your keywords.
- Combination of Tools: Integrate machine learning methods and online tools to obtain more robust results.
- Process Automation: Implementing automated solutions is ideal for companies handling large amounts of content. A common strategy is combining Python and NLTK with machine learning algorithms that can process data continuously.
- A/B Testing in SEO Content: For websites, testing different keyword combinations and analyzing the resulting traffic helps to identify the most effective strategies.
Conclusion
Extracting keywords from a text is essential for optimizing content and understanding semantic relevance in any type of text. Options range from basic frequency methods to complex machine learning techniques. Regardless of your experience level, there are accessible tools and techniques for any user, from free online options to advanced Python programs.
References
Hongwiengchan, W., & Qu, J. . (2023). Comparison of Keywords Extraction Techniques in Kickstarter and Indiegogo Projects. INTERNATIONAL SCIENTIFIC JOURNAL OF ENGINEERING AND TECHNOLOGY (ISJET), 7(1), 41–47.
Jayasiriwardene, T. D., & Ganegoda, G. U. (2020, September). Keyword extraction from Tweets using NLP tools for collecting relevant news. In 2020 International Research Conference on Smart Computing and Systems Engineering (SCSE) (pp. 129-135). IEEE.
Jiang, Y., Xiang, C., & Li, L. (2024). Keyword Acquisition for Language Composition Based on TextRank Automatic Summarization Approach. International Journal of Advanced Computer Science & Applications, 15(4).
Liu, J., & Jiang, T. (2023). Research on Symptomatic Treatment Decision Support System Based on Natural Language Process (NLP) for Medication Guidance. In Advances in Biomedical and Bioinformatics Engineering (pp. 656-661). IOS Press.
Pascual Espada, J., Solís Martínez, J., Cid Rico, I., & Emilio Velasco Sánchez, L. (2023). Extracting keywords of educational texts using a novel mechanism based on linguistic approaches and evolutive graphs. Expert Systems With Applications, 213, 118842. https://doi.org/10.1016/j.eswa.2022.118842
Wu, P., Tang, T., Zhou, L., & Martínez, L. (2024). A decision-support model through online reviews: Consumer preference analysis and product ranking. Information Processing & Management, 61(4), 103728. https://doi.org/10.1016/j.ipm.2024.103728
Zou, Z.; Ji, X.; Li, Y. 2024. A Framework Model of Mining Potential Public Opinion Events Pertaining to Suspected Research Integrity Issues with the Text Convolutional Neural Network model and a Mixed Event Extractor. Information 2024, 15, 303. https://doi.org/10.3390/info15060303
Editor and founder of “Innovar o Morir” (‘Innovate or Die’). Milthon holds a Master’s degree in Science and Innovation Management from the Polytechnic University of Valencia, with postgraduate diplomas in Business Innovation (UPV) and Market-Oriented Innovation Management (UPCH-Universitat Leipzig). He has practical experience in innovation management, having led the Fisheries Innovation Unit of the National Program for Innovation in Fisheries and Aquaculture (PNIPA) and worked as a consultant on open innovation diagnostics and technology watch. He firmly believes in the power of innovation and creativity as drivers of change and development.